
Introduction
In the same way that is possible to read and write data from snowflake inside databricks, its also possible to use databricks with query federation against diverse SQL engines, including snowflake. The current supported engines are:
We are going to demonstrate how it works with Snowflake. We will first create a table in databricks, it can be a delta table stored in the data lake, or an unmanaged table pointing to a set of files (External Table) or anything in between.
Creating the required resources
I will go to databricks and run the following:
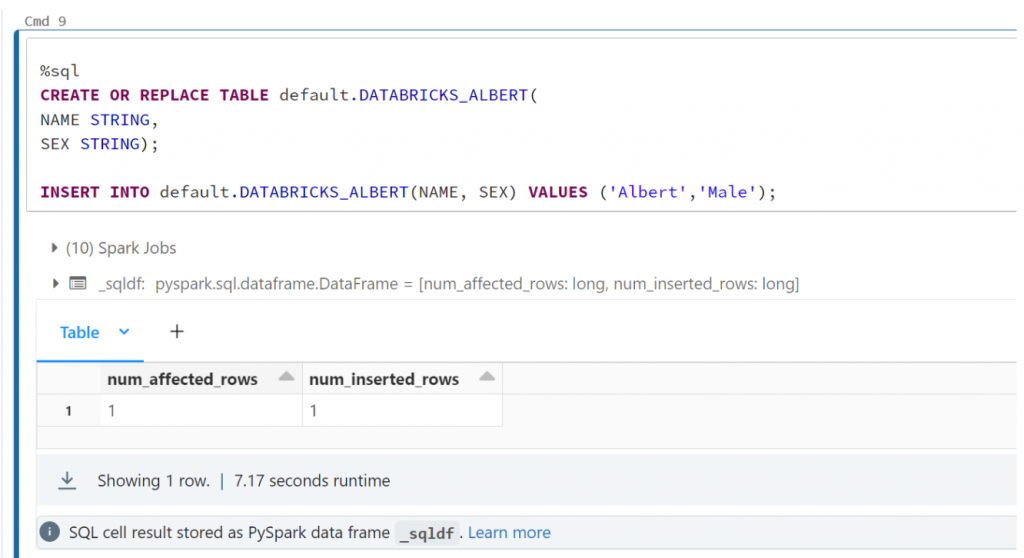
CREATE OR REPLACE TABLE default.DATABRICKS_ALBERT(
NAME STRING,
SEX STRING);
INSERT INTO default.DATABRICKS_ALBERT(NAME, SEX) VALUES ('Albert','Male');This process can either be done from the Data Engineering persona or the SQL persona. I created it first from the data engineering part.
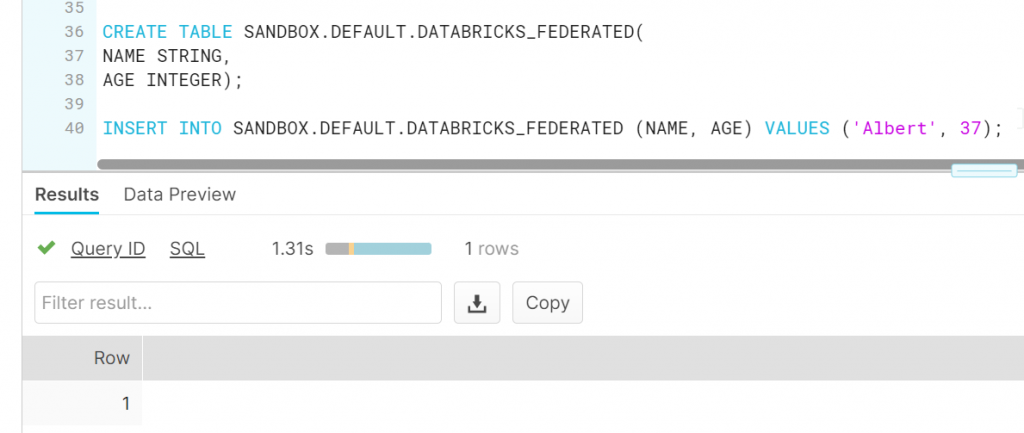
Now we go to snowflake and create a second table which we want to join:
CREATE TABLE SANDBOX.DEFAULT.DATABRICKS_FEDERATED(
NAME STRING,
AGE INTEGER);
INSERT INTO SANDBOX.DEFAULT.DATABRICKS_FEDERATED (NAME, AGE) VALUES ('Albert', 37);And it gets created succesfully:
Now we can stay in the data engineering persona or go to databricks SQL and we create the virtual table that will create the link with the table in snowflake. This will do the mapping:
CREATE TABLE MY_TABLE
USING snowflake
OPTIONS(
dbtable 'YourTable',
sfURL 'yourURL.snowflakecomputing.com', --You can use privatelink if you have one
sfUser 'YourUser',
sfPassword 'YourPassword',
sfDatabase 'YourDB', --You can use a secret scope like: secret('scope_name', 'pwd_entry'),
sfSchema 'YourSchema',
sfWarehouse 'YourSnowflakeWarehouse'
);In the Databricks SQL:
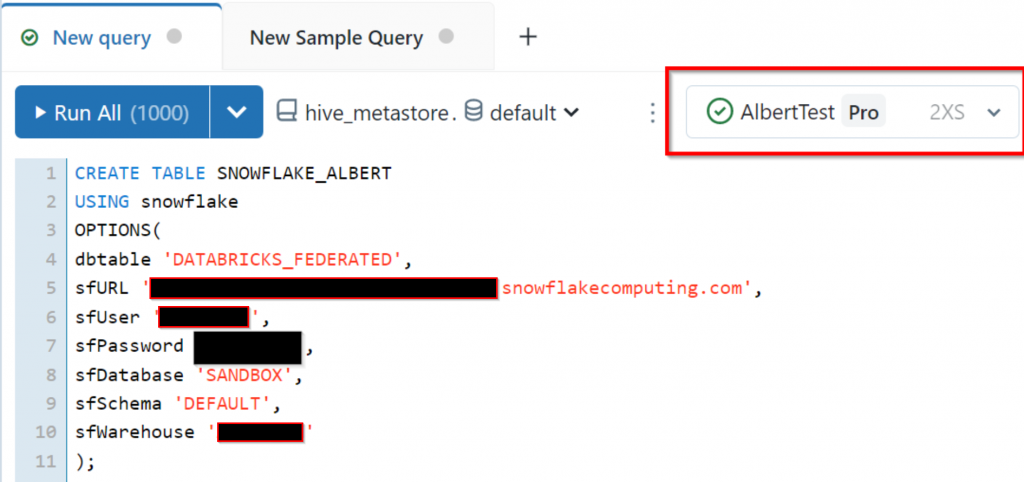
In The Data Engineering:
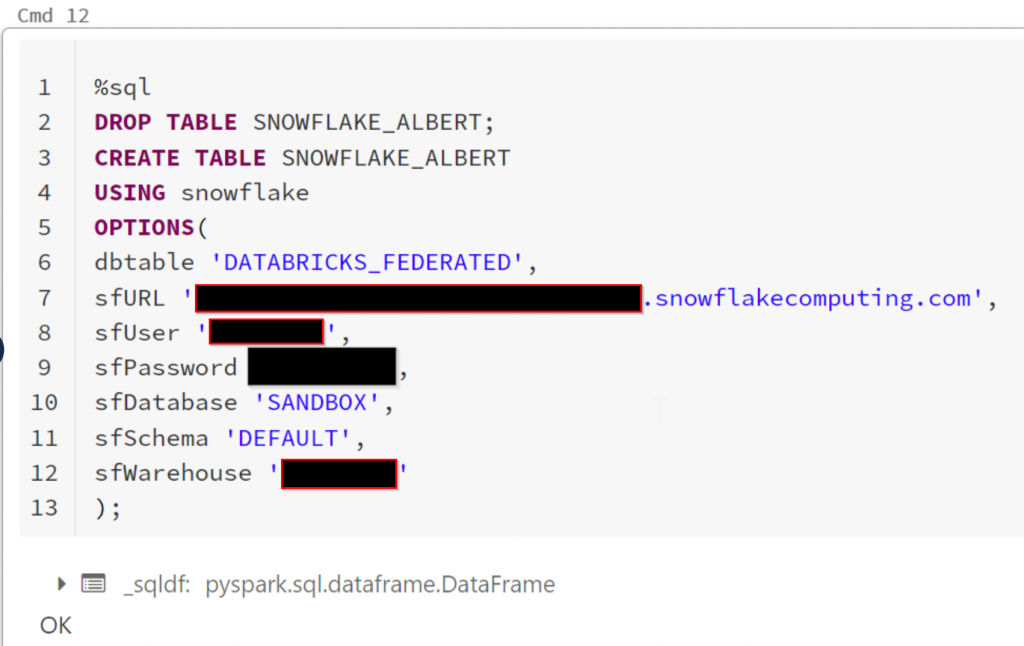
Glueing it up together
If you use Databricks SQL I couldn’t make it work with the STARTER ENDPOINT so be sure to use a normal WAREHOUSE to avoid any errors. In my case i created an XS warehouse, but now i can run a query fetching data from both tables:
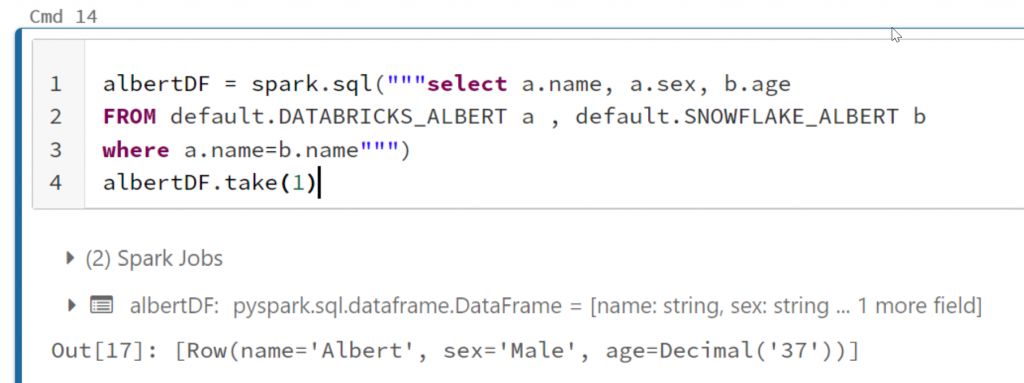
select a.name, a.sex, b.age
FROM default.DATABRICKS_ALBERT a , default.SNOWFLAKE_ALBERT b
where a.name=b.name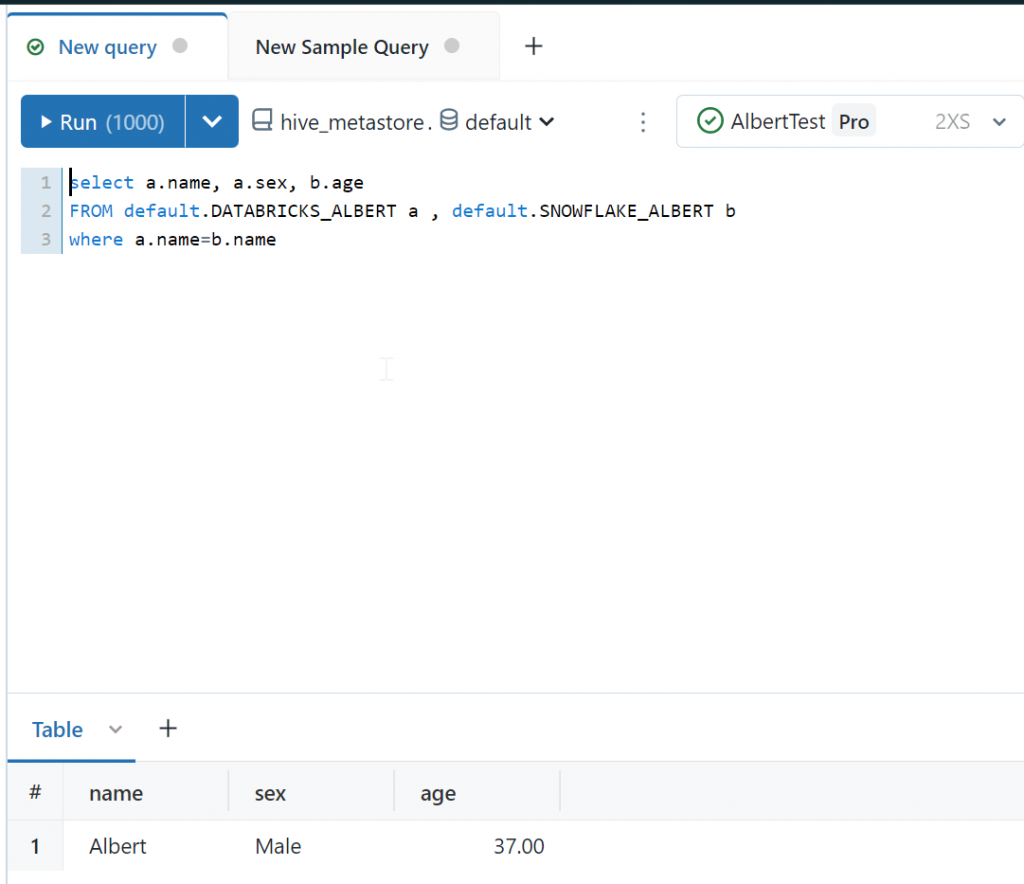
And in the Data Engineering Persona:
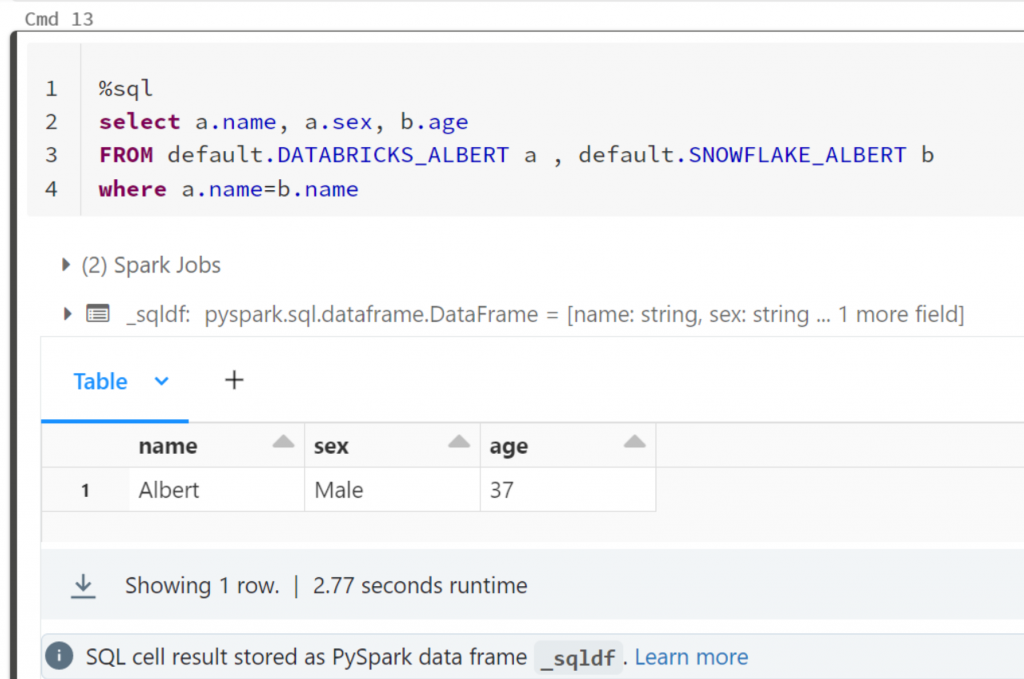
And of course you can use spark.sql with python or any other language to query the table as well:
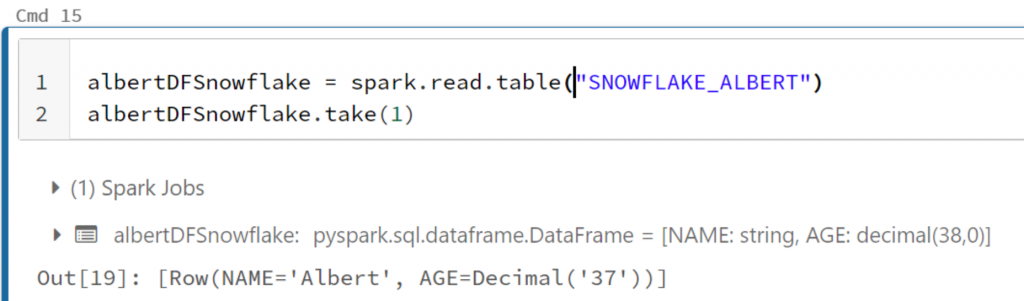
Or directly with Dataframes treating the federated table as any other table in the catalog:
Hope this clears your way and helps you integrate data from different sources without having to use a virtual metadata layer.